
tg-me.com/knowledge_accumulator/116
Last Update:
Chip Placement with Deep Reinforcement Learning [2020] - ещё одна демонстрация ограниченности нашего мозга
Люди нашли, в каких ситуациях RL отлично подходит - в решении некоторых "NP-задач" - когда вариантов решений очень много, при этом их можно осмысленно генерировать по частям. Также важно умение быстро проверять качество решения. Я уже писал про такие случаи в постах про AlphaTensor и AlphaDev.
Ради любопытства и улучшения интуиции давайте взглянем на ещё один пример, в котором это круто работает, а также подумаем о причинах успеха. Сегодняшняя "игра" - это проектирование чипов.
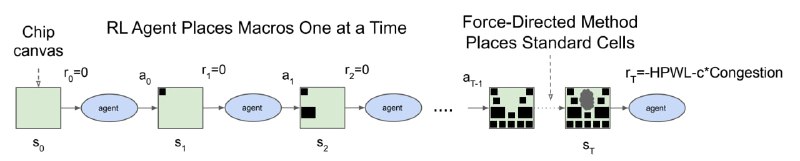
Мы начинаем с пустого "холста", и на нём один за одним располагаем элементы микросхемы, пока не расположим весь набор. После этого результат подвергается постобработке и, наконец, подсчёту награды - производится приблизительный расчёт того, насколько данная микросхема хороша, например, по суммарной длине проводов.
Пространством действий являются всевозможные позиции на холсте, на которые можно расположить текущий элемент. Состояние - это вся информация о микросхеме и уже расположенных элементах, графовая структура микросхемы, мета-фичи микросхемы и т.д. Награды нулевые на каждом шаге, кроме последнего, и там это просто мера качества результата, описанная выше.
В результате PPO, один из распространённых RL-алгоритмов, значимо обходит человека по итоговым метрикам. Почему же так получается? Заблюренные иллюстрации в статье дают на это очевидный ответ - наш интеллект не умеет решать всю задачу целиком, он вынужден разбивать её на небольшое количество кусков и затем решать каждый из них по отдельности, возможно, проделывая декомпозицию на нескольких уровнях. Итоговые микросхемы получаются у человека понятными и красивыми, тогда как алгоритм, который "на ты" с многомерными пространствами, сооружает адское месиво из тысячи компонентов, которое мы не в состоянии понять. Но оно лучше работает, а это самое главное.
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
tg-me.com/knowledge_accumulator/116